[수학적 최적화] 시뮬레이션 담금질 Simulated Annealing의 이해와 파이썬 코드
수학적 최적화Mathematical optimization
수학적 최적화는 최적 조건을 만족하는 정의역의 원소를 찾는 방법 (혹은 그에 대한 분야) 입니다. 이렇게만 설명하면 약간 불 명확한데 아래와 같이 정의하면, 그 의미가 분명해 집니다.
정의역을 $A$로 하는 함수 $f : A \rightarrow \mathbb{R}$ 가 주어졌을 때, 임의의 $x \in A$에서 $f(x_{min}) \le f(x)$를 만족하는 $x_{min}$를 찾는 방법
위에서 함수 $f$를 주로 목적 함수Objective function 이라고 부릅니다. 정의역 집합 $A$는 실공간일 수 도 있고, 혹은 임의의 집합일 수 도 있습니다. 위 정의에서는 목적 함수가 최소값이 되는 $x_{min}$를 찾은 것을 표현하였는데, 경우에 따라서는 목적 함수가 최대값이 되는 $x_{max}$를 찾는 문제를 접할 수 도 있습니다. 목적 함수가 최대값이 되게 하는 $x_{max}$를 찾는 문제는 $f \rightarrow -f$로 변환하면 최대값을 찾는 문제는 최소값을 찾는 문제가 됩니다.
이전 포스팅 https://studyingrabbit.tistory.com/60
수학적 최적화 수치해법으로 풀어보는 변분법 문제 : 최단 하강 곡선
변분법은 주어진 범함수의 값을 극대 혹은 극소로 만드는 범함수의 입력 변수인 함수를 찾는 방법입니다. 조금 형식적으로 쓴다면, 함수 $$f(x) : x \ \in [a, b] \rightarrow y \in V \subset \mathbb{R} $$ 가 주
studyingrabbit.tistory.com
에서는 변분법에 대해서 알아 보았는데, 변분법은 최적화의 한 분야 입니다. 위에서 정의역 집합 $A$를 함수 공간으로 생각한다면(물론 보다 정교한 정의가 필요합니다) 최적화 문제는 변분법의 문제가 됩니다.
수학적 최적화는 수학, 자연 과학, 공학 뿐 아니라 매우 넓은 분야의 학문과 공학의 분야에서 활용됩니다. 중학교나 고등학교 시절 부터 "함수의 최소값 혹은 최대값"을 찾는 문제를 수 없이 많이 풀어 봤으며, 미분이 가능한 함수인 경우, 극대값 혹은 극소값은 미분값이 0이 되는 지점이라는 것을 배워 왔습니다. 단지 학문과 공학의 분야 뿐 아니라, 일상생활에서도 우리는 항상 (보통의 경우 많은 사람들은) "인생의 행복을 최대화" 하기 위해 살아가고 있습니다.
수학적 최적화 그 자체에 대한 넓은 설명은 사실 끝이 없어서, 이만 줄이도록 하겠습니아. 아마도 이 포스팅을 검색을 통해서 보시는 분이라면 수학적 최적화가 무엇인지 그리고 수학적 최적화의 의미와 목적이 무엇인지를 이미 아시고 계실거라 추측합니다.
수치해법을 활용한 수학적 최적화Numerical Optimization
교과서 수준의 연습 문제가 아닌, 실제로 의미 있는 최적화 문제에서 목적함수는 매우 복잡한 형태로 주어 집니다. 해석적인 형태로 쓸 수 없을 때도 있거니와 시뮬레이션 등을 통해 매우 시간이 오래 걸리고 복잡한 방식으로 목적함수의 값을 구애햐 하는 경우도 많습니다. 따라서 해석적인 방법(미분을 통해서 극대, 극소값을 구하고 이를 비교하는 방법)으로는 문제를 풀 수 없고, 거의 대부분의 경우에는 컴퓨터를 이용해서 풀게 됩니다.
매우 많은 컴퓨터를 이용한 수학적 최적화 알고리듬이 제안되었는데, 그 뜻은 특정한 하나의 매우 훌륭한 최적화 알고리듬이 없다는 것과 거의 동치 입니다. 그 어떤 최적화 알고리듬 보다도 좋은 알고리듬이 있었다면, 그 최고의 알고리듬을 제외하고는 다른 알고리듬은 모두 사장되었을 것 입니다. 그러나 새로운 최적화 알고리듬은 아직까지도 많이 만들어지고 있으며, 연구되고 있습니다. 목적함수의 성격에 따라서 그에 꼭 맞는 최적화 알고리듬은 다르며, 동일한 최적화 알고리듬을 사용하여 문제를 푼다고 하더라도, 그 최적화 알고리듬에서 사용하는 변경 가능한 파라미터의 값에 따라서 결과가 달라지기도 합니다. 말 그대로 "그 때 그 때 테스트를 해 보고 그나마 제일 좋은 알고리듬을 사용" 하는 수 밖에 없습니다.
시뮬레이션 담금질 Simulated Annealing
이번 포스팅에서 구체적으로 알아볼 최적화 알고리듬은 시뮬레이션 담금질, 영어로는 simulated annealing입니다. 보통의 학문 용어가 그렇듯 한국어 번역 보다는 영어 발음 그 자체로 "시뮬레이티드 어닐링" 이라고 부릅니다.
담금질은 금속을 가공하는 과정에서 사용되는 방법입니다. 예를들어 철을 가공한다고 한다면, 철에 높은 온도를 가해서 철을 녹인 다음에 천천히 식히면 철의 강도가 강해지고 철의 고유한 성질이 더 잘 나타나게 됩니다. 이는 철이 서서히 식으면서 결정화 되는 과정에서 녹이기 전의 철에서 있었던 불순물이 사라지거나 불균일 했던 결정 구조가 균일해 지면서 철의 고유한 성질이 발현되기 때문입니다. 철을 고온으로 높혀 액체 상태를 만들면, 철 원자들은 마구 잡이 운동을 합니다. 그러다가 온도가 점점 낮아지면 철 원자의 운동 에너지가 낮아지게 되고, 다른 원자와의 상호작용으로 인해 결정 구조를 갖게 됩니다. 작은 영역에서 결정 구조가 만들어지면, 그 구조를 점점 주변으로 퍼지게 되는데 서서히 식히는 과정을 통해 주변에 있던 원자들도 이미 만들어진 결정 구조에 따라서 자리를 잡게 되고, 전체에 걸쳐서 하나의 결정 구조가 생성 됩니다.
만일 철을 급하게 식히게 된다면, 완벽한 결정 구조가 만들어지지 않거나 서로 다른 결정 구조가 만들어 질 수 있습니다. 혹은 충분히 고온으로 올리지 않는다면 철 원자가 보다 안정적인 결정 구조를 갖는 위치로 옮겨지기 전에 운동을 멈추고 이상한 형태의 결정 구조를 가질 수 있습니다. 따라서 훌륭한 담금질을 위해서는 온도를 충분히 높혀주고, 천천히 식히는 과정이 필요합니다.
시뮬레이션 담금질은 위에서 설명한 재료 공학에서의 담금질에 영감을 받아서 만들어진 최적화 알고리듬 입니다. 위에서 말로 설명하 과정을 물리학의 한 분야인 통계역학의 언어를 통해 설명하면 다음과 같습니다. 특정한 크기를 갖는 철 조각에는 아보가드로 수 정도의 철 원자가 있습니다. 그 철을 구성하고 있는 원자들의 위치를 $x$ 라고 쓸 수 있습니다. $x$는 매우 차원이 높은 유클리드 공간의 한 점이 됩니다. 철 원자들들이 위치 $x$에 있을 때, 시스템의 에너지(철 원자의 운동에너지와 철 원자들 끼리의 상호작용 에너지의 합)을 $E(x)$라 쓸 수 있습니다. 철의 온도를 $T$라고 한다면, 통계역학의 정리에 따라서, 원자들의 위치가 $x$일 확률은 $e^{-\frac{E(x)}{k_BT}}$에 비례 합니다. 여기서 $k_B$는 볼츠만 상수로 온도와 에너지를 연결해 주는 물리 상수 입니다.
온도 $T$가 매우 높다면, 철 원자들의 위치는 그러한 배치의 에너지에 상관 없이 동등하게 됩니다. (이는 위 식에서 $T \rightarrow \infty$를 생각하면 됩니다) 반대로 온도 $T$가 매우 낮다면, 가장 가능성이 있는 상태는 가장 에너지가 낮은 상태에 대응되는 철 원자들의 위치 $x_{min}$가 됩니다. 따라서 철 원자들의 위치 상태 $x$를 통계역학의 물리법칙에 따라서 "움직이면서" 서서히 온도를 낮추게 되면 $x_{min}$를 얻을 것으로 기대할 수 있습니다.
시뮬레이션 담금질 알고리듬의 순서
정의역 집합 $A$에서 정의된 목적함수 $f : A \rightarrow \mathbb{R}$의 최소값 $x_{min} = \arg \min_{x \in A} f(x)$를 시뮬레이션 담금질 알고리듬에 따라 어떻게 구하는지 설명하도록 하겠습니다. 편의상 $A$를 상태의 집합, $x$를 하나의 상태로 칭하도록 하겠습니다. $A$는 $n$ 차원 유클리드 공간의 부분집합일 수 도 있고, 수열의 집합, 혹은 특정한 조합의 집합일 수 도 있습니다.
0. 초기 온도 $T$를 선택한다.
초기 온도는 목적함수의 크기에 따라 적절하게 잘 정해야 합니다. "적절하게 잘"은 문제에 따라서 달라지는데, 이에 대해서는 아래에서 다시 자세히 다루도록 하겠습니다.
1. 초기 상태 $x$를 선택 한다.
초기 상태는 특정한 규칙을 이용해서 선택할 수 도 있고, 아니면 그냥 정의역의 원소 중에서 하나를 무작위로 뽑을 수 도 있습니다.
2. 초기 상태 $x$에 대한 목적함수의 값 $E = f(x)$를 구한다.
3. 새로운 상태 $x_{new}$를 선택 한다.
새로운 상태를 뽑는 규칙은 시뮬레이션 담금질의 성능을 결정하는 매우 중요한 요소 중 하나 입니다. 집합 $A$에서 완전히 무작위로 $x_{new}$를 뽑아 낼 수 도 있고, 혹은 상태 $x$에 따라 특정한 규칙을 부여하여 $x_{new}$를 뽑을 수 도 있습니다. 이에 대해서는 아래에서 다시 자세히 다루도록 하겠습니다.
4. 새로운 상태 $x_{new}$에 대한 목적함수 값 $E_{new} = f(x_{new})$를 구한다.
5. $P = e^{-\frac{E_{new} - E}{T}}$ 계산 한다.
6. 0과 1 사이의 임의의 수 $r \in [0,. 1]$ 를 하나 뽑고, $r \lt P$이면, $x \leftarrow x_{new}$로 $x$의 값을 바꾸고, 그렇지 않으면 아무 것도 하지 않는다. 또한, 온도 $T$를 조금 낮춘다. 즉 $T \leftarrow T-dT$
7. 2에서 부터 6까지의 과정을 계속 반복한다. 그 과정에서 얻은 $f(x), f(x_{new})$의 값이 특정한 값으로 수렴을 하거나, 원하는 값보다 작아진 경우, 과정을 종료한다.
위에서 말로 설명한 것을 의사코드pseudo code로 옮기면 아래와 같습니다.
T = T_initial
x = rand(A)
E = f(x)
while (Not Converge):
x_new = candidate(x)
E_new = f(x_new)
P = exp(-(E_new - E) / T)
r = rand([0, 1])
if r <= P:
x = x_new
else:
pass
T = reduce(T)
def rand(set):
return "one of element in the set"
위 과정에 대한 설명
1. 메트로폴리스-헤이스팅스 알고리듬
시뮬레이션 담금질 알고리듬은 몇 가지의 굵직한 구성 요소로 이루어져 있는데, 각 구성 요소를 설명 하도록 하겠습니다.
우선 편의를 위해서 온도 $T$를 서서히 줄이는 것이 아니라, 특정한 온도 $T$로 고정을 하고 위 의사코드에서 While문의 조건이 항상 True라고 가정을 하도록 하겠습니다. 그러면 While문 안에 있는 과정이 계속 해서 수행됩니다. 또한, While문 안에 있는 과정을 수행하는 동안 생성된 $x$를 버리지 않고 메모리에 모두 저장해 두었다고 하겠습니다. 만일 그렇다면, 이렇게 해서 생성된 $x$ 의 분포는 온도가 $T$일 때의 정준 앙상블Cannonical emsemble 분포를 따르게 됩니다. 왜냐하면 위 시뮬레이션 담금질에서 $x_{new}$를 선택하고, $x_{new}$를 $x$로 업데이트 하는 과정은 정확히 메트로폴리스-헤이스팅스 알고리듬을 활용하여 정준 앙상블 분포를 얻는 과정이기 때문입니다. 메트로폴리스-헤이스팅스 알고리듬과 이를 이용하여 정준 앙상블 분포를 얻는 것에 대한 내용은 이전 포스팅
https://studyingrabbit.tistory.com/35
메트로폴리스-헤이스팅스 알고리듬을 활용한 분포 생성 및 이를 이용한 몬테 카를로 적분
기각 샘플링 기반 몬테 카를로 적분이 부정확한 예시 지난 시간에 소개한 기각 샘플링 방법을 통해서 $$A = \int_{-\infty}^{\infty} x^2 \frac{1}{\sqrt{2 \pi}} e^{-\frac{x^2}{2}}dx$$ 을 해 보도록 하겠습니다. $f(x)
studyingrabbit.tistory.com
https://studyingrabbit.tistory.com/58
몬테 카를로 시뮬레이션을 이용하여 통계 역학의 문제 풀기 (1) : 토이 모델 예시
지난 세 번의 포스팅을 통해서 몬테 카를로 시뮬레이션에 대해서 알아봤습니다. https://studyingrabbit.tistory.com/33?category=911605 몬테 카를로 시뮬레이션(Monte Carlo Simulation) 의 이해 : 원주율값 구하기 (+
studyingrabbit.tistory.com
을 참고 하면 됩니다.
온도 $T$에서 $x$의 분포가 정준 앙상블을 따른다고 한다면, 각 $x$의 빈도는 $e^{-\frac{f(x)}{T}}$ 에 비례하게 됩니다.
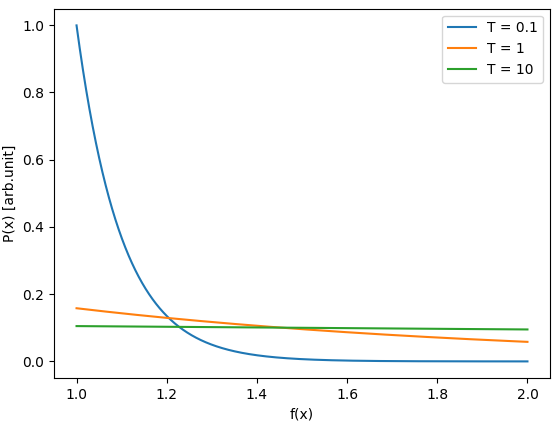
위 그래프는 정준 앙상블에서 상태의 $f(x) \in [1, 2]$ 값에 따른 상태의 확률을 서로 다른 $T$값에 따라 보여주고 있습니다. 서로 다른 두 상태 $x_1, x_2$의 목적 함수가 $f_1, f_2$ 일 때, 상태 $x_1, x_2$의 확률의 비 $\frac{P_1}{P_2}$는
$$\frac{P_1}{P_2} = e^{-\frac{f_1 - f_2}{T}}$$
가 됩니다. 만일 $f_1 \lt f_2$ 라고 한다면, 이 값은 $1$보다 큰 값이 됩니다. $f_1 - f_2$가 고정 되어 있을 때, $\frac{P_1}{P_2}$의 값은 $T$의 값에 따라 크게 달라지는데, 만일 $T$가 매우 큰 값이라면, $\frac{P_1}{P_2} \approx 1$ 이 되고, $T$가 매우 작은 값이라면, $\frac{P_1}{P_2} \rightarrow \infty$가 됩니다. 이를 이해한다면, 위 그래프에서 온도에 따른 $P(x)$가 왜 저렇게 나타나는지 알 수 있습니다. $T$가 매우 크다면, 각 상태의 확률은 각 상태의 목적 함수 값에 무관하게 균등한 분포를 보이며, 반대로 $T$가 매우 작다면, 목적 함수가 작은 경우 상태의 확률은 커지지만, 목적 함수가 큰 경우에는 확률은 거의 0이 됩니다. 만일 극단적으로 $T$가 작아져서 0에 가까운 값이 된다면, 목적 함수가 가장 작은 경우에는 확률 값이 0이 아니지만, 목적 함수의 값이 조금이라도 커지게 된다면 0에 가까운 값이 됩니다. $T \rightarrow 0$ 에서의 상태의 확률의 분포는
$$P(x) =
\begin{cases}
1, & \text{if } x = x_{min} = \arg \min_{x \in A} f(x)\\
0, & \text{otherwise }
\end{cases}$$
가 됩니다. 즉 $T \rightarrow 0$에서 정준 앙상블의 분포는 목적 함수가 가장 낮은 상태 $x$에 국한되는 분포를 보입니다. 다시 말하면, $T \rightarrow 0$에서 샘플링 되는 상태는 목적 함수가 가장 낮은 상태가 됩니다.
최적화의 목적은 $x_{min}$을 찾는 것이니, $T \rightarrow 0$ 에서의 정준 앙상블 분포를 따르는 $x$의 샘플링을 찾으면 됩니다. 그러나 위 의사 코드에서 볼 수 있듯, 시뮬레이션 담금질 알고리듬에서는 $T$를 처음에는 큰 값으로 잡고, 서서히 줄이는 방법을 택하고 있습니다. 이는 $T \rightarrow 0$에서의 정준 앙상블 분포를 한 번에 만들어 내기가 어렵기 때문입니다. 또한, 특정 온도에서 정중 앙상블 분포를 만들어 내기 위해서는 매우 다양한 상태 $x$에 대한 목적 함수 $f(x)$를 계산해야 하는데, 이 과정에서 계산 시간이 무척 오래 걸리기 때문입니다.
2. 목적 함수가 큰 상태로 이동 할 수 도 있다.
위 의사 코드의
P = exp(-(E_new - E) / T)
r = rand([0, 1])
if r <= P:
x = x_new
부분은 기존의 상태 $x$에서 새로운 상태의 후보 $x_{new}$로 상태를 옮길 것($x \leftarrow x_{new}$)인지 말 것($x = x$) 인지를 결정하는 부분입니다. 기존 상태의 목적 함수 $f(x)$ 보다 새로운 상태의 후보의 목적 함수 $f(x_{new})$가 더 작다면, 즉 $f(x_{new}) \lt f(x)$라면, $P$ 값은 $1$ 보다 크게 되고 $r$ 값에 상관 없이($r \le 1$ 이므로), 새로운 상태의 후보가 후보가 아닌 실제 상태가 됩니다. 즉 $x \leftarrow x_{new}$가 되고 절차를 계속 반복합니다. 그렇지 않고 $f(x_{new}) \gt f(x)$이면, 실제로 계산된 $P$ 값의 확률에 따라 새로운 상태로 상태를 옮길 것인지 아닐지를 결정합니다. 다시 말하면 새로운 상태의 후보에 해당되는 목적 함수가 기존의 상태에 해당하는 목적 함수 보다 더 크더라고 하더라도, 새로운 상태의 후보로 상태를 옮길 가능성이 있는 것입니다. 물론 새로운 상태의 후보에 해당하는 목적 함수의 값이 무척 크다면, 새로운 상태의 후보로 상태를 옮길 가능성은 무척 작습니다. 최적화의 목적이 목적 함수를 작게 만드는 것이기에, 이와 같이 목적 함수가 큰 상태로 옮겨 가는 것은 이상해 보입니다. 그러나 이 과정이 메트로폴리스-헤이스팅스 알고리듬의 핵심임과 동시에 시뮬레이션 최적화의 핵심이 됩니다.
목적 함수가 큰 상태로의 이동이 불가능 하다면, 메트로폴리스-헤이스팅스 알고리듬에서는 정준 앙상블 분포를 얻을 수 없습니다. 최적화의 관점에서 본다면, 목적 함수가 큰 상태로 이동하는 것은 국소 최소점local minimum을 빠져 나오는 역할을 합니다. 최적화 알고리듬의 가장 큰 적은 최적화 알고리듬으로 찾는 해가 국소 최소점으로 수렴하는 것 입니다. 특히 기울기 기반 gradient based 알고리듬에서 빈번히 일어나는 현상인데, 주어진 상태에서 단순히 목적 함수가 낮은 곳으로만 상태를 변경한다면, 수렴된 상태가 국소 최소점일 가능성은 매우 높습니다. 따라서, 전역 최소점global minium을 찾기 위해서는 국소 최소점을 "빠져나와야 할" 필요가 있고, 국소 최소점에서 빠져 나오기 위해서는 목적 함수가 높은 상태로의 이동이 가끔씩 일어나야 합니다. 물론, 이 이동이 너무 빈번하게 일어난다면 수렴성이 나빠지기 때문에 "적당한 빈도"로만 목적 함수가 높은 상태로의 이동이 있어야 하는데, 시뮬레이션 담금질에서는 $P = e^{-\frac{E_{high} - E_{low}}{T}}$의 확률로 이동을 시켜 줍니다. 대충 말하면, 새로운 상태의 후보에 해당하는 목적 함수가 현재 상태의 목적 함수 보다 $T$ 정도 크다면, 목적 함수가 크더라도 상태를 변경할 수 있는 것이죠.
3. 초기 온도의 설정과 온도를 잘 낮추는 방법
초기 온도는 충분히 높아야 합니다. 그래야 모든 상태를 한 번씩은 "확인" 할 수 있기 때문입니다. 앞에서 설명한 것 처럼, 온도 $T$가 정의역의 모든 상태들에 해당하는 목적 함수 보다 크다면, 즉 $E \gt f(x), x \in A$, 각 상태에 해당하는 확률 $P(x) = e^{-frac{f(x)}{T}}$는 $x$에 크게 상관 없이 거의 균일한 값을 갖게 될 것 입니다. 그러면, 상태를 업데이트 하는 과정에서 거의 랜덤하게 상태를 이동하게 되고, 이 과정을 많이 반복 한다면 정의역 $A$의 거의 모든 상태를 한 번씩 점유할 것 입니다. 이렇게 해야 전역 최소점을 찾을 확률이 높아 집니다.
또한 온도를 천천히 낮추는 것도 중요합니다. 온도를 너무 급격히 낮추게 된다면, 온도를 급격히 낮추기 시작한 과정에 있던 상태 근처의 국소 최소값으로 상태가 수렴할 수 있기 때문입니다.
온도를 낮추는 구체적인 방법은 다양하지만, 가장 쉽게 구현할 수 있는 것은 지수적으로 줄이는 방식입니다. 즉, 반복 횟수를 $n$이라고 할 때,
$$T = T_0 e^{-n/n_0}$$
와 같은 방식으로 $T$를 감소 시키는 것 입니다. 여기서 $T_0$는 초기 온도 값, $n_0$는 온도가 낮아지는 정도를 결정하는 매개 변수 입니다.
4. 새로운 상태의 후보를 결정하는 방법 (위 의사코드에서 candidate(x)라고 쓴 함수)
온도를 매우 천천히 낮추고, 특정 온도에서 상태를 옮기는 시도를 매우 많이 한다면, 새로운 상태의 후보를 결정하는 방법에 상관 없이 시뮬레이션 담금질 알고리듬은 전역 최소점을 찾아 낼 것 입니다. 그러나, 현실적인 사용에서는 목점 함수를 계산 하는 횟수는 제한적이 됩니다. 따라서, 가장 효율적인 방법으로 온도를 낮추고, 새로운 상태의 후보를 결정하는 방법을 고안해야 합니다.
가장 쉽게 생각할 수 있는 방법은 정의역 $A$에서 임의의 상태를 하나 뽑아 내는 것 입니다. 이 방법은 개념적으로 생각하기 쉽고, 정의역의 상태 $A$의 거의 모든 상태를 확인 해 볼 수 있다는 장점이 있습니다. 그러나, 수렴성에서 문제가 생깁니다. 즉, 상태가 너무 중구난방으로 업데이트 될 수 있기 때문에 목적함수를 낮추는 방향으로의 이동의 가능성이 떨어 질 수 있습니다.
다른 방법으로는 현재의 상태의 주변에서 새로운 상태의 후보를 뽑아 내는 것 입니다. 이를 구현하는 다양한 구체적인 방법이 있을 수 있으나, 역시 가장 간단한 방법은 특정한 거리값 $d$를 정해 두고, $|x_{new} - x | \le d$를 만족하는 $x_{new}$를 무작위로 뽑는 것 입니다. $d$가 작다면, 새로운 상태의 후보는 원래 상태의 매우 주변에서 선택될 것이며, $d$가 크다면, 새로운 상태의 후보는 원래 상태에서 조금 먼 거리에 있는 상태도 선택 될 수 있을 것 입니다. 만일 $d$의 크기가 정의역 $A$의 지름 보다 크다면, 이 방법은 위에서 설명한 "완전히 랜덤하게 뽑는 방법"과 동일해 집니다. $d$를 작게 잡는 다면 상태의 변화가 크지 않게 되고, 따라서 특정한 값에 빠르게 수렴할 가능성이 높아집니다. 하지만, 상태의 변화가 크지 않기 때문에, 수렴된 해가 국소 최소점일 가능성이 높습니다. 그렇다고 $d$를 크게 잡으면 "완전히 랜덤하게 뽑는 방법"에서의 단점이 그대로 재현될 것 입니다. 이 방법에서는 $d$를 어떻게 잡느냐가 관건이 됩니다.
파이썬을 통한 알고리듬의 구현과 실제 예시
시뮬레이션 담금질의 코드는 매우 간단하기 때문에, 파이썬과 같은 쉬운 프로그래밍 언어도로 매우 쉽게 구현할 수 있습니다. 위 의사 코드가 실제 프로그램의 코드와 다르지 않을 정도로 간단합니다. 아래는 실제로 파이썬을 통해 구현한 코드 입니다. 코드의 각 부분에 주석을 달아 두었습니다. 코드 전체를 복붙해서 실행하면 시뮬레이션 담금질 시뮬레이션의 애니메이션이 실행 됩니다.
# 필요한 라이브러리 불러 오기
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import animation
import random
# matplotlib 디스플레이 설정
plt.style.use('dark_background')
# objective function 정의
def objective(x, type):
if type == 'sphere':
return objective_sphere(x)
elif type == 'sin_x':
return objective_sin_x(x)
# spherical function 문제의 objective function
def objective_sphere(x):
f = (x**2.0).sum()
return f
# local minimum이 있는 문제의 objective function
def objective_sin_x(x):
f = np.prod(np.sin(np.pi*x)) + 0.5*(x[0] - x[1])
return f
# 새로운 상태로 이동의 확률을 계산 하는 부분
def transition_probability(e, e_new, T):
de = e_new - e
p = np.exp(-de/T)
return p
# 새로운 상태로 이동할 것인지 아닌지를 결정하는 부분
def transition_or_not(p):
r = np.random.random()
if p > r:
return True
else:
return False
# matplotlib 애니메이션 관련 부분
def update(num, Z, list_E, list_T, point, point_history, line, time_text):
point_history.set_offsets(Z[:num])
point.set_offsets(Z[num])
line.set_data(Z[num-10:num, 0], Z[num-10:num, 1])
time_text.set_text("Iteration = {}\nObjective = {:.4f}\nTemperature = {:.4f}".format(num, list_E[num], list_T[num]))
# 실제 시뮬레이션 담금질 실행 함수
def real_valued_function():
N = 2 # 2차원 문제
T = 10 # 초기 온도
d = 0.2 # 새로운 상태를 결정하는 방법에서 사용되는 매개 변수
X = np.random.random(N)*2-1 # 초기 상태
Niteration = 1000 # 반복 횟수
T_reduce = 10**(-5/Niteration) # 온도를 낮추는 것과 관련된 매개 변수 설정
N_display = 500 # 애니메이션 총 프래임 횟수 설정
N_sampling = Niteration//N_display
# 목적 함수의 형태를 선택
# objective_type = 'sphere'
objective_type = 'sin_x'
# 그래프를 그리기 위한 정보를 담아 두는 리스트
list_X, list_E, list_T = [], [], []
# 시뮬레이션 담금질의 반복 과정 수행
for iteration in range(Niteration):
X_new = X + (np.random.random(N)*d-d/2) # 새로운 상태를 정의
X_new = np.clip(X_new, -1, 1) # 새로운 상태가 정의역 안에 존재하도록 함
# 알고리듬에서 필요한 각종 값들을 계산
e = objective(X, objective_type)
e_new = objective(X_new, objective_type)
p = transition_probability(e, e_new, T)
bool_transition = transition_or_not(p)
if bool_transition:
X = X_new
T *= T_reduce
# 각 과정에서 X, E, T 값을 저장해 둠
list_X.append(X)
list_E.append(e)
list_T.append(T)
print(iteration, e, T)
# 애니메이션에 사용할 프래임을 샘플링
list_X = list_X[::N_sampling]
list_E = list_E[::N_sampling]
list_T = list_T[::N_sampling]
list_X = np.array(list_X)
# 아래는 애니메이션을 그리는 코드
# matplotlib 코드임
fig = plt.figure(figsize=(8, 8))
ax = plt.axes()
###########################
### spherical objective ###
###########################
if objective_type == 'sphere':
delta = 0.01
x = np.arange(-1.0, 1.0, delta)
y = np.arange(-1.0, 1.0, delta)
X, Y = np.meshgrid(x, y)
Z = X**2.0 + Y**2.0
CS = ax.contour(X, Y, Z, cmap=plt.get_cmap("bwr"))
ax.clabel(CS, inline=1, fontsize=10)
ax.scatter([0], [0], color = 'blue')
elif objective_type == 'sin_x':
delta = 0.01
x = np.arange(-1.0, 1.0, delta)
y = np.arange(-1.0, 1.0, delta)
X, Y = np.meshgrid(x, y)
Z = np.sin(np.pi * X) * np.sin(np.pi * Y) + 0.5*(X-Y)
CS = ax.contour(X, Y, Z, cmap=plt.get_cmap("bwr"))
ax.clabel(CS, inline=1, fontsize=10)
point_history = ax.scatter([], [], s=10, color='lime', zorder=0, alpha = 0.5)
point = ax.scatter([], [], s=40, color='lime', zorder = 1)
line, = ax.plot([], [], color='lime', lw = 3)
time_text = ax.text(0.05, 0.90, '', transform=ax.transAxes, fontsize='large')
ax.set_xlim(-1,1)
ax.set_ylim(-1,1)
# ax.legend(loc = 'lower right')
ani = animation.FuncAnimation(fig, update, len(list_X), fargs=(list_X, list_E, list_T, point, point_history, line, time_text), interval=10, blit=False)
# ani.save('d.gif', writer=animation.PillowWriter(fps=300))
plt.show()
plt.close('all')
plt.plot(range(len(list_E)), list_E, color='yellow', label='SA')
# plt.axhline(0.0, color='lime', lw=1, ls='--', label='exact')
plt.xlabel("Iteration")
plt.ylabel("Objective")
plt.legend()
plt.grid(lw=1, color='gray')
plt.show()
if __name__ == '__main__':
real_valued_function()
위 코드는 목적 함수 $f$가
$$f(x) = \sin(\pi x) \sin(\pi y) + \frac{1}{2}(x-y), (x,y) \in [-1,1] \times [-1,1]$$
와 같이 정의 됐을 때, 이 목적 함수의 최소값을 찾는 코드 입니다.
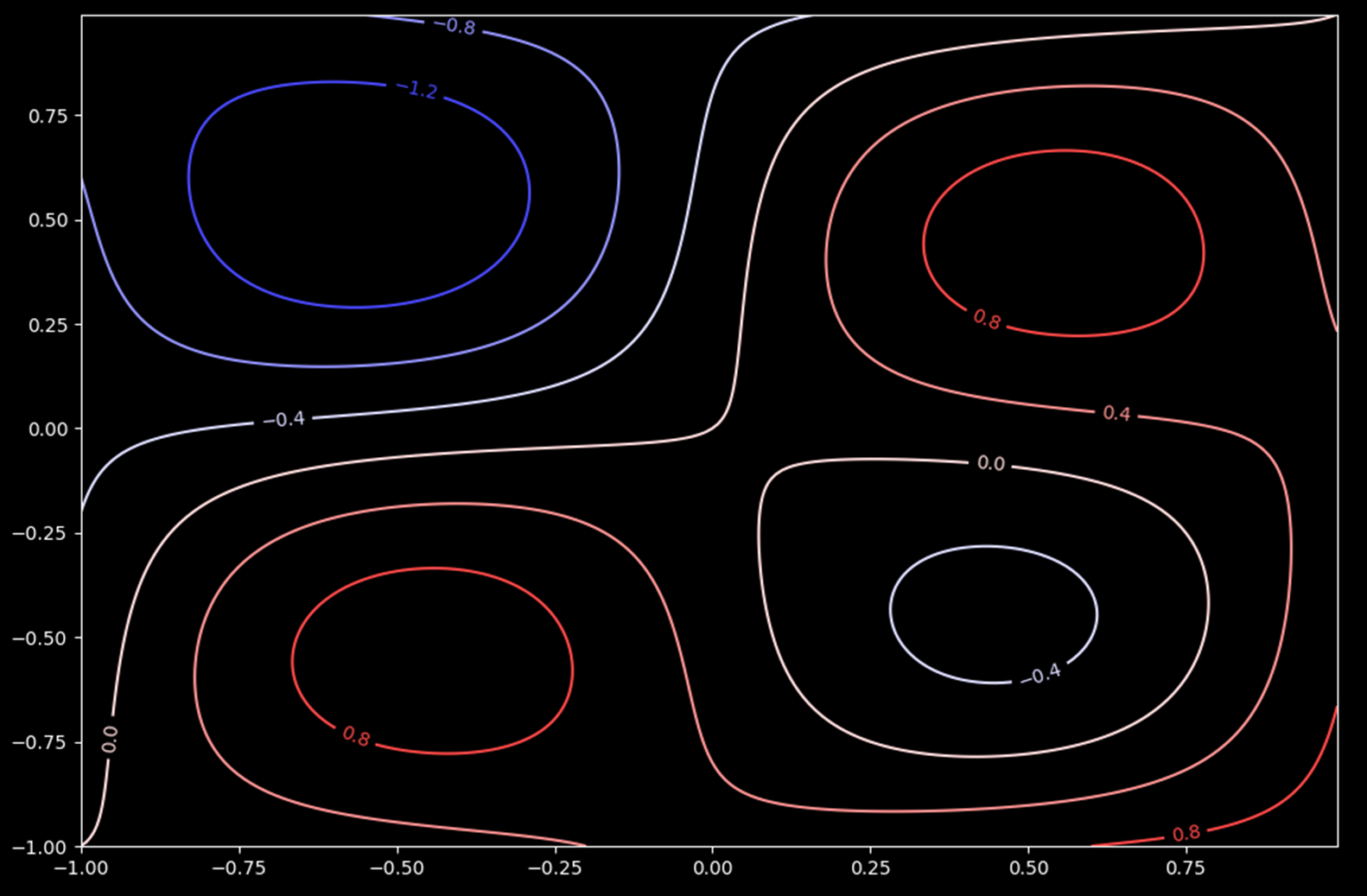
위 그래프는 목적 함수 $f$의 등고선을 그린 것 입니다. 등고선의 값은 색깔로 표시하였는데, 파란색 < 흰색 < 붉은색 순서입니다. 이 목적 함수는 제 2사분면에 전역 최소값(global minimum)을 갖고, 제 4사분면에 국부 최소값(local minium)을 갖습니다. 목적 함수의 정의역이 2원 닫힌 집합인 간단한 문제이지만, 국부 최소값이 있다는 점에서 약간의 "어려움"이 있는 목적 함수 입니다.
새로운 상태(위치)$(x_{new}, y_{new})$는 기존의 상태 $(x_{old}, y_{old})$에서 주변 위치로 무작위 하게 조금 이동한 것 입니다. 정확히는
$$x_{new} = x_{old} + 0.1 \cdot r_1$$
$$y_{new} = y_{old} + 0.1 \cdot r_2$$
이며, 여기서 $r_1, r_2$는 $[-1,1]$에서 임의의 실수를 하나 택한 것 입니다. 파이썬 코드를 아시는 분이라면, 이 부분을 쉽게 이해하실 수 있을 것 입니다.
시뮬레이션 담금질을 통한 목적 함수의 전역 최소값 찾기 예시와 설명
위 코드를 실행하면, 아래와 같은 애니메이션을 얻습니다. 시뮬레이션 담금질의 반복 상태를 동영상으로 나타낸 것 입니다.
위 시뮬레이션에서는 목적 함수의 전역 최소값을 정확하게 찾습니다!
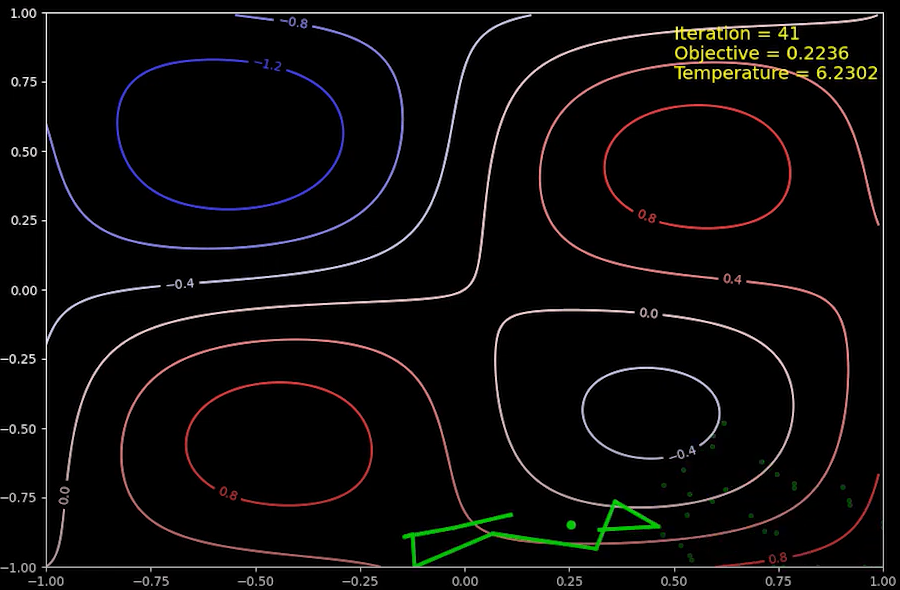
시뮬레이션 초기의 위치 값은 임의로 주어지게 되는데, 초기 위치는 국소 최소값이 존재하는 제 4사분면으로 결정 되었습니다. 상태(위치)는 이전 상태(위치)에서 조금씩 이동할 수 있기에 반복 계산의 초기에 상태는 제 4사분면에 머물게 됩니다. 애니메이션을 갭쳐한 이미지의 오른쪽 상단에 현재 반복 횟수(Iteration), 목적 함수의 값(Objective), 온도(Temperature) 값이 기록됩니다.
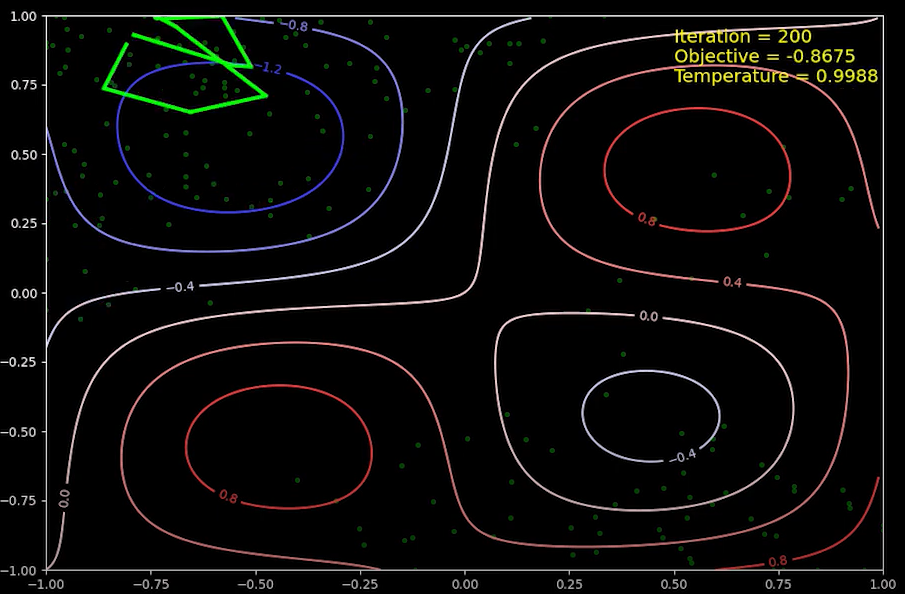
2000번 반복을 한 뒤의 상태입니다. (정확히는 2,000번 반복을 하였는데, 애니메이션에서는 10번 반복 당 하나의 점만 표시하였습니다. 그래서 애니메이션에서는 200번째 반복 입니다) 제 4사분면에서 시작한 상태는 제 1사분면을 거쳐, 전역 최소값이 있는 제 2사분면으로 옮겨 왔습니다. 시뮬레이션 초기에는 온도 값이 크기 때문에, 국소 최소값이 있는 부분에서 최고값이 있는 부분 (제 1사분면)으로 상태가 쉽게 이동할 수 있습니다. 이와 같이 상태가 목적 함수가 큰 정의역의 상태로 이동할 수 있다는 것이 시뮬레이션 담금질의 특징으로, 이 같은 이동을 통해서 국소 최소값이 있는 영역에서 전역 최소값이 있는 영역으로 상태가 옮겨 갈 수 있습니다.
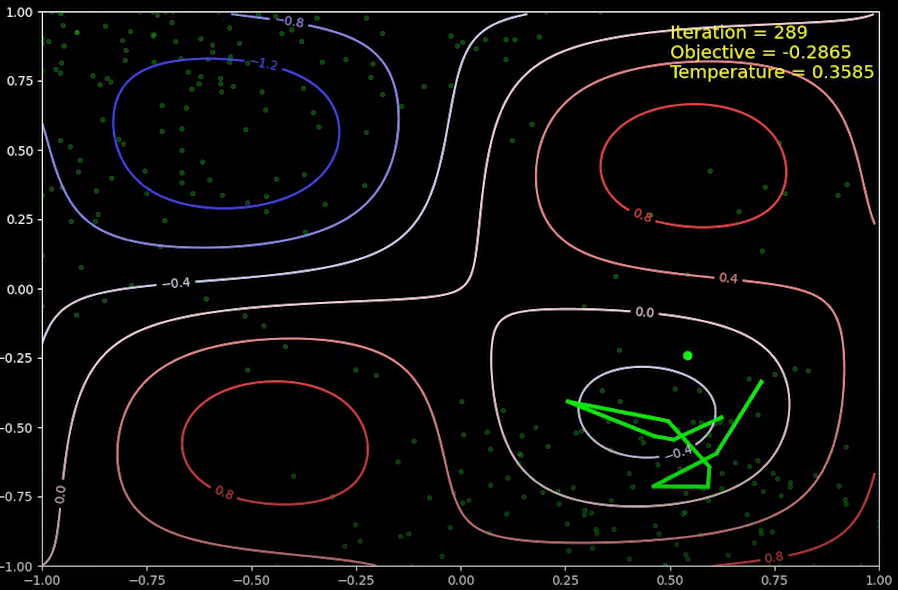
289번째 반복에서의 상태 입니다. 200번째 반복에서 상태는 전역 최소값 부근에 있었지만, 위에서 설명한 것과 같은 논리로, 전역 최소값의 영역을 벗어나 제 3사분면을 거쳐, 국소 최소값이 있는 제 4사분면으로 다시 돌아 왔습니다.
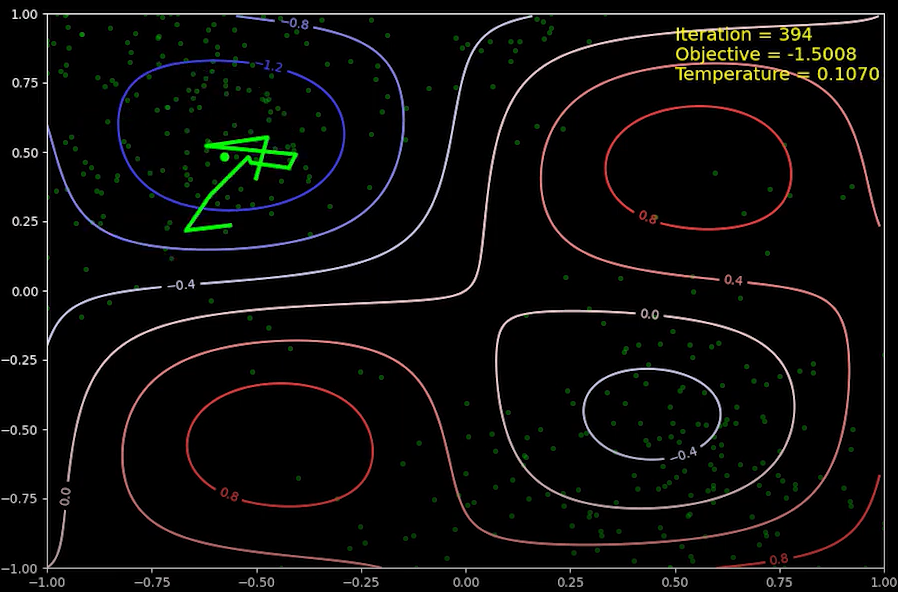
약 400번째 반복 후 상태입니다. 국소 최소값 영역에서 다시 제 1사분면을 거쳐 전역 최소값 영역으로 상태가 옮겨졌습니다. 이 때의 온도는 약 0.1 이고, 이 때 부터는 목적 함수값이 더 큰 곳으로 이동할 수 있는 가능성이 매우 낮아 집니다. 위 그림의 등고선 값은 목적 함수값의 간격이 0.4 마다 그려져 있는데, 온도가 0.1일 때, 현재 상태의 목적 함수 보다 목적 함수 값이 0.4 만큼 더 높은 상태로의 이동이 실현이 되는 확률은 $e^{-\frac{0.4}{0.1}} = e^{-4} \approx 0.018$ 입니다. 즉, 대략 50번 정도 시도를 하면 한 번 실현이 되는 확률입니다. 따라서, 이 반복 시점 부터는 계속 해서 전역 최소값 영역 근처에서 상태가 바뀌게 되며, 온도가 낮아 짐에 따라 (반복을 계속 함에 따라) 더 낮은 목적 함수 값을 갖는 곳으로 조금씩 이동하게 됩니다.
확률이 매우 낮긴 하지만, 0이 아니기 때문에, 목적 함수값이 0.4만큼이나 더 큰 상태로 이동이 가능 할 수 있습니다. 그러나, 적어도 이 문제에서는 전역 최소값 영역에서 국소 최소값 영역으로 이동하기 위해서(가장 빠르게 이동하는 방법은 원점 주변을 거쳐서 이동하는 것 입니다)는 대략 1.6 정도가 되는 목적 함수 장벽 (barrier)를 넘어야 합니다. 이번 시뮬레이션에서 한 번의 상태 이동에서 좌표값을 바꿀 수 있는 값은 $0.1$로, 전역 최소값 (이 점은 대략 $(-0.5, 0.5)$ 입니다)에서 목적 함수 장벽의 중심 (이 점은 대략 $(0, 0)$ 입니다)으로 이동하기 위해서는 5번의 이동을 거쳐야 합니다. 5번의 이동에서 1.6 만큼의 목적 함수 증가가 있어야 하니, 이는 평균적으로 약 0.3 정도의 에너지 증가에 해당합니다. 온도가 0.1일 때, 목적 함수가 0.3 만큼 증가하는 상태로 이동하는 확률은 $e^{-3} = 0.05$ 이고, 이 확률로의 상태 변화가 5번 연속으로 일어나야 하기 때문에 (물론 연속으로 5번 일어나지 않아도 되긴 합니다) 그 확률은 $0.05^5 = 0.0000003$ 로 거의 0에 가깝습니다. 온도가 더 낮아진다면, 그 확률은 현실적으로 일어나지 않을 확률일 것 입니다.
물론 위 논의에서 사용한 목적 함수의 차이 0.4 혹은 온도 0.1 은 이 문제에 해당하는 값으로, 실제 문제에서는 다른 값이 사용될 것 이고, 그에 따라서 완전히 다른 양상, 즉 전역 최소값 영역에서 국소 최소값 영역으로 상태가 이동하는 것, 이 일어 날 수 도 있습니다. 물론 그 가능성은 낮습니다.
같은 논리로, 온도가 낮은 시점에서 상태가 국소 최소값 영역에 한 번 빠지게 된다면, 그 후에도 계속 해서 국소 최소값 근처에 존재하게 됩니다. 이 경우에는 다시 시스템의 온도를 높였다가 낮추는 방법도 고려 해 볼 수 있습니다. 물론 이렇게 된다면 계산을 해야하는 반복 횟수가 증가되게 됩니다.
이 부분에서 설명한 사항이 시뮬레이션 담금질의 핵심이 되는 것으로, 이 부분을 제대로 이해하지 못 한다면 다시 한 번 차근히 읽어 보길 권정합니다.
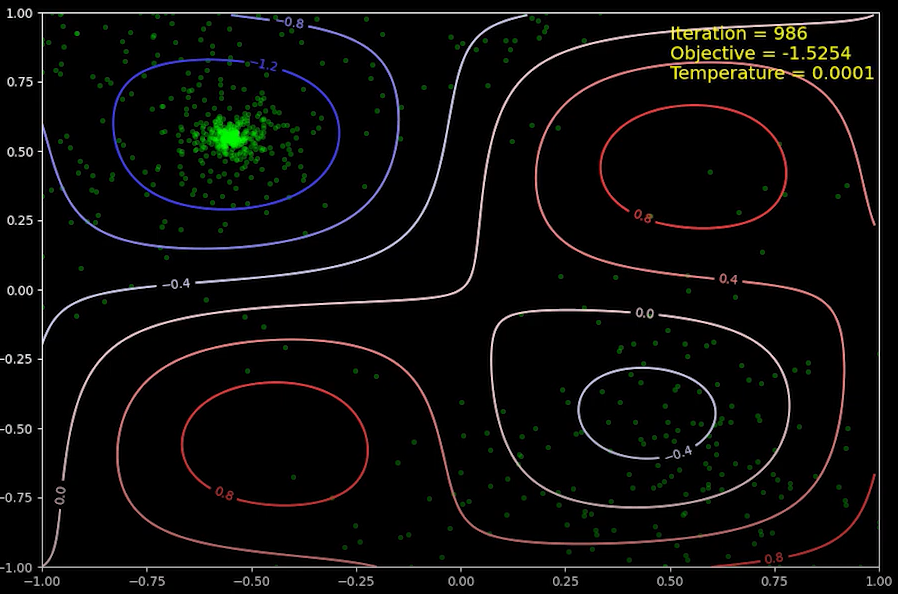
(거의) 최종 상태인 반복 횟수가 986회 일때의 상태입니다. 앞서 말한대로, 전역 최소값 근처에서 조금이라도 목적 함수가 더 낮은 상태를 찾아서 상태를 옮겨 다니다 보니, 전역 최소값 근처에 점들이 매우 많습니다. 목적 함수를 해석적인 식으로 정의 했기 때문에, 미분을 통해서 전역 최소값을 구할 수 있는데, 이 값은 시뮬레이션 담금질을 통해서 얻은 값과 일치합니다.
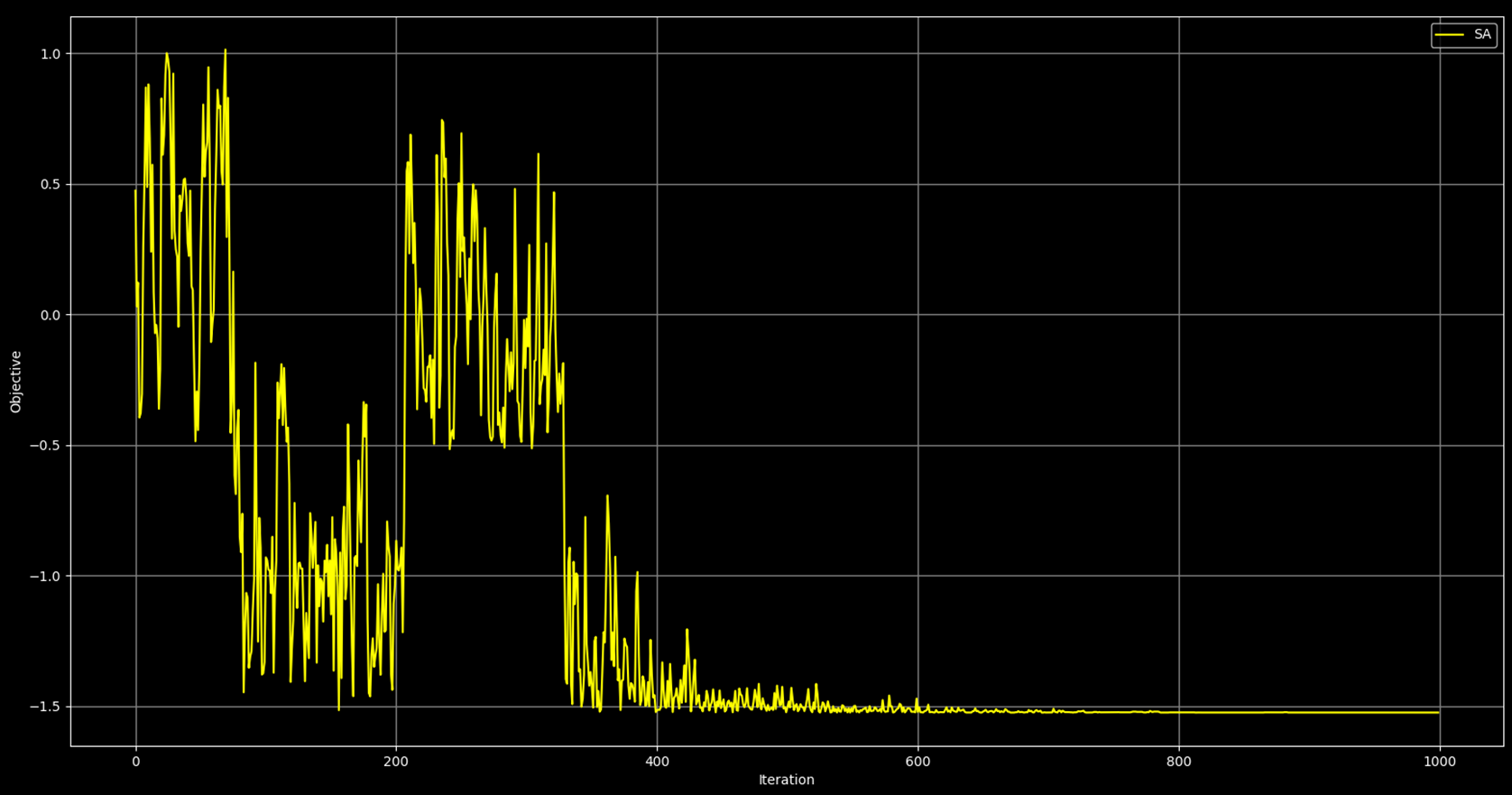
전체 과정의 진행에 따른, 각 과정에서의 목적 함수의 값을 그래프로 그리면 위와 같습니다. 위 그래프의 개형은 앞에서 설명한 과정의 진행과 일치합니다. 반복 횟수가 100 ~ 200 사이에는 상태가 국소 최소값 근처에 머문 경우이며, 반복 횟수가 대략 350회 이후에는 상태가 전역 최소값 부근을 찾게 되고, 이 다음 부터는 정확한 전역 최소값을 찾게 됩니다. 반복 횟수가 대략 800회 이후 부터는 목적 함수 값의 변화가 없는데, 이는 시뮬레이션 담금질이 목적 함수의 전역 최소값을 발견 했기 때문입니다.
시뮬레이션 담금질의 성질 정리
시뮬레이션 담금질 알고리듬은 전역 최소값을 찾을 수 있는 수학적 최적화의 한 방법입니다. 담금질이라는 물리적인 과정에서 착안하여, 전역 최소값을 찾는 방법으로 국소 최적화에 빠지지 않고, 전역 최소값을 찾을 수 있다는 장점이 있습니다. 또한, 알고리듬을 코드로 옮기는 과정이 간단하기 때문에 쉽게 시험삼아서 활용해 볼 수 있다는 장점이 있습니다.